Combining In-Process Events with AWS SQS for a Hybrid Event-Driven Architecture
We needed both instant in-process reactions and reliable async processing. Here's how we built a hybrid event system using Node.js EventEmitter and AWS SQS.
Some things need to happen immediately. When an agent publishes a campaign, the timeline should update in the same request. Other things can wait. Syncing campaign statistics from Facebook’s API or processing a large contact import shouldn’t block the user.
A single event strategy doesn’t cover both. We ended up with a hybrid: in-process events for the fast stuff, AWS SQS for the heavy stuff.
The problem
Utogi’s domain modules interact constantly. Publishing a campaign means notifying the timeline, updating statistics, syncing with external providers, maybe triggering accounting entries. Some of that has to happen before the API responds. The rest is background work.
If everything runs synchronously, every downstream reaction adds latency to the response. If everything goes through a message queue, even a simple timeline update pays the cost of serialization, network hops, and queue polling. Neither option alone works.
The hybrid approach
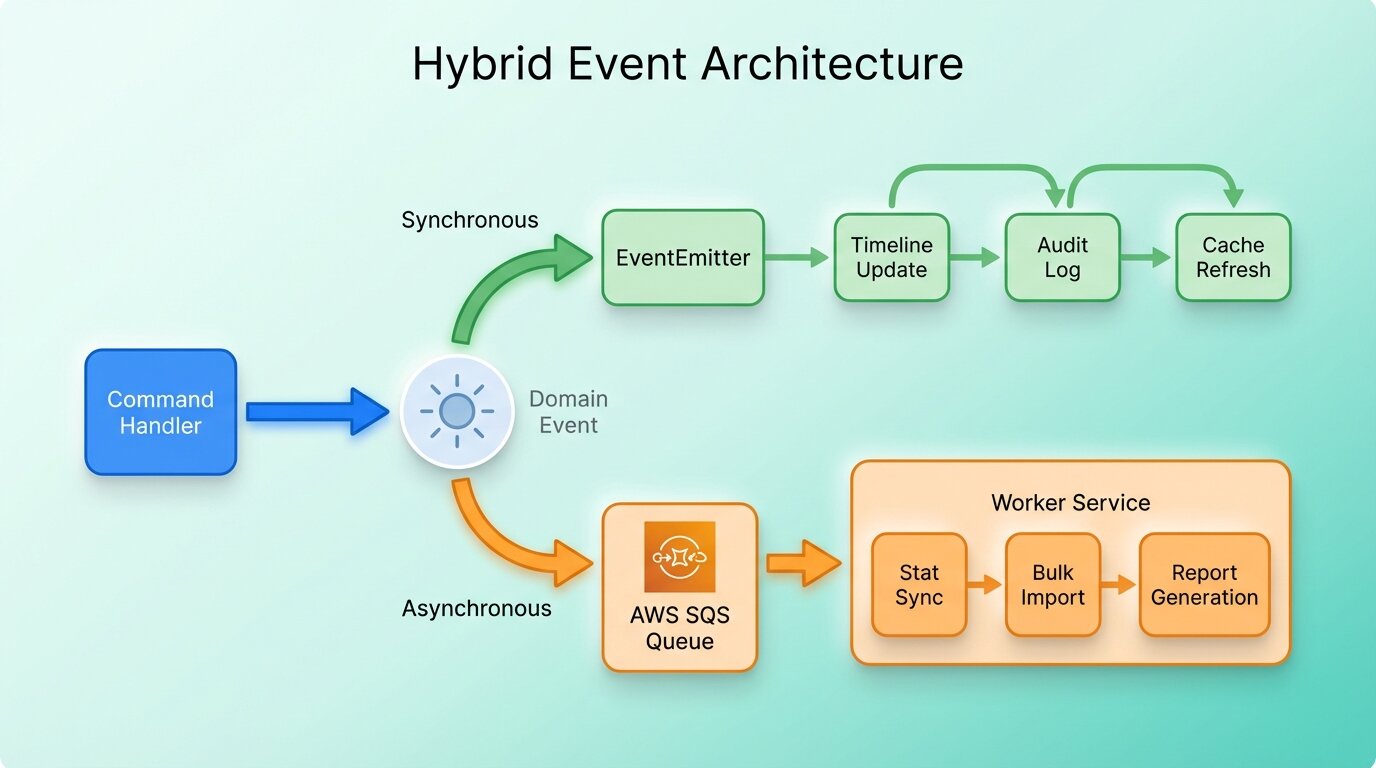
Two mechanisms, each doing what it’s good at:
Node.js EventEmitter handles in-process domain events. A command handler finishes its work, emits an event, and listeners in the same process react right away: updating a timeline, creating an audit entry, refreshing a cache. Fast stuff that needs to finish within the request.
AWS SQS handles the expensive work. Syncing campaign stats from external marketing platforms, processing bulk imports, generating reports. These get dispatched to a queue, and a separate worker service picks them up.
How domain events flow
It starts in a command handler. After the business logic runs (creating a campaign, updating a contact), the handler emits a domain event. Each module registers its own listeners, so the handler stays decoupled from whatever happens next.
Some listeners handle the event inline, like updating a timeline record or creating a notification. Others push a message to SQS for the worker to deal with later. The command handler doesn’t know which path a reaction takes, and it shouldn’t.
We have a pub/sub abstraction layer (we call it the Transporter pattern) that sits over both mechanisms. The emitting code just publishes an event. The transport layer routes it to the right place.
The worker service
The worker runs as its own Docker container next to the API. It uses sqs-consumer to poll SQS queues and process messages. Keeping heavy processing out of the API process is the whole point; otherwise, one big import would slow down everyone’s requests.
The worker shares the same codebase and domain modules as the API. Same database, same models, same business logic. The difference is what it boots up: event processors and queue consumers instead of HTTP controllers and GraphQL resolvers.
In production, both run as separate ECS tasks. The API scales on request volume, the worker scales on queue depth.
Challenges
Event ordering
SQS standard queues don’t guarantee ordering. Usually this doesn’t matter for us. Processing campaign stats out of order is fine. For the few cases where order matters (sequential state transitions), we check the current status in the handler before processing. If the entity has already moved past the expected state, we skip the message.
Idempotency
Messages can arrive more than once. Every SQS handler has to handle that. For stat syncs it’s natural, since we fetch fresh data from the provider anyway. For other operations, we use deduplication keys to detect and skip repeats.
Error handling
In-process listener fails? The error propagates up to the command handler, and the whole operation rolls back. SQS handler fails? The message goes back on the queue for retry. After enough failures, it lands in a dead-letter queue.
One thing we learned the hard way: distinguish between retryable failures (network timeouts, rate limits) and permanent ones (invalid data, deleted resources). Retrying a permanent failure just fills the dead-letter queue with noise.
Local development
The full event flow involves Docker containers, SQS queues, and worker processes. Our Docker Compose setup runs all of it locally: the API, the worker, ElasticMQ (SQS-compatible), and PostgreSQL. You can trace an event from the API through the queue to the worker without deploying anything.
Debugging event chains
This was the hardest part. A user reports a bug, and the cause is buried three events deep. Event A triggers handler B, which emits event C, which the worker picks up in handler D. We added correlation IDs: a unique ID generated at the start of every request, passed through every handler and every SQS message. Searching logs by correlation ID gives you the full chain.
What we learned
- Start with in-process events. Most domain reactions are fast enough to handle synchronously. Only move to SQS when the operation is actually expensive or can tolerate delay.
- Make every event handler idempotent, whether in-process or queued. A handler that fails mid-execution will run again.
- Add correlation IDs from day one. Without them, debugging anything that crosses a service boundary is miserable.
- Give the worker its own monitoring. Queue depth, processing time, failure rates, dead-letter queue size. A worker that fails silently is worse than having no worker.
- Run the full stack locally with Docker Compose. It catches integration issues before they reach production, and it makes event-driven code much less painful to develop against.