Building a Real Estate SaaS with Domain-Driven Design and CQRS in Node.js
How we architected a 168K-line TypeScript codebase with 37 domain modules using DDD and CQRS, and why the upfront investment paid off over years of development.
When your codebase crosses 100K lines of TypeScript, you either have architecture or you have a mess. Utogi is a real estate operating system that’s been in continuous development across three companies and two countries. It manages properties, contacts, marketing campaigns, accounting, territory mapping, and door-knocking workflows for agencies across Australia and New Zealand.
At 168K lines with 37 domain modules, it could easily be unmaintainable. It isn’t, and that comes down to two decisions we made early: Domain-Driven Design and CQRS.
The problem
Real estate marketing involves a lot of business domains that interact in messy ways. Properties have contacts. Contacts have buyers. Buyers trigger campaigns. Campaigns run on multiple marketing platforms. Campaigns generate expenses. Expenses feed into commission calculations. And all of this is scoped to offices within franchise groups.
A naive monolith where everything shares a single service layer and database access pattern would fall apart within months. We needed clear boundaries between business domains, and we needed different strategies for reading data (dashboards, reports, search) versus writing it (creating campaigns, importing contacts, publishing listings).
When we started building Utogi in 2019, the Node.js ecosystem didn’t have mature backend frameworks for this kind of thing. NestJS existed and had a CQRS module, but it wasn’t yet proven, and its performance was slow compared to a leaner custom setup. Most Node.js projects at the time were flat route-handler-talks-to-database codebases built on Express. We had to build our own architectural scaffolding, drawing from patterns more common in .NET and Java and adapting them to TypeScript.
Why DDD + CQRS
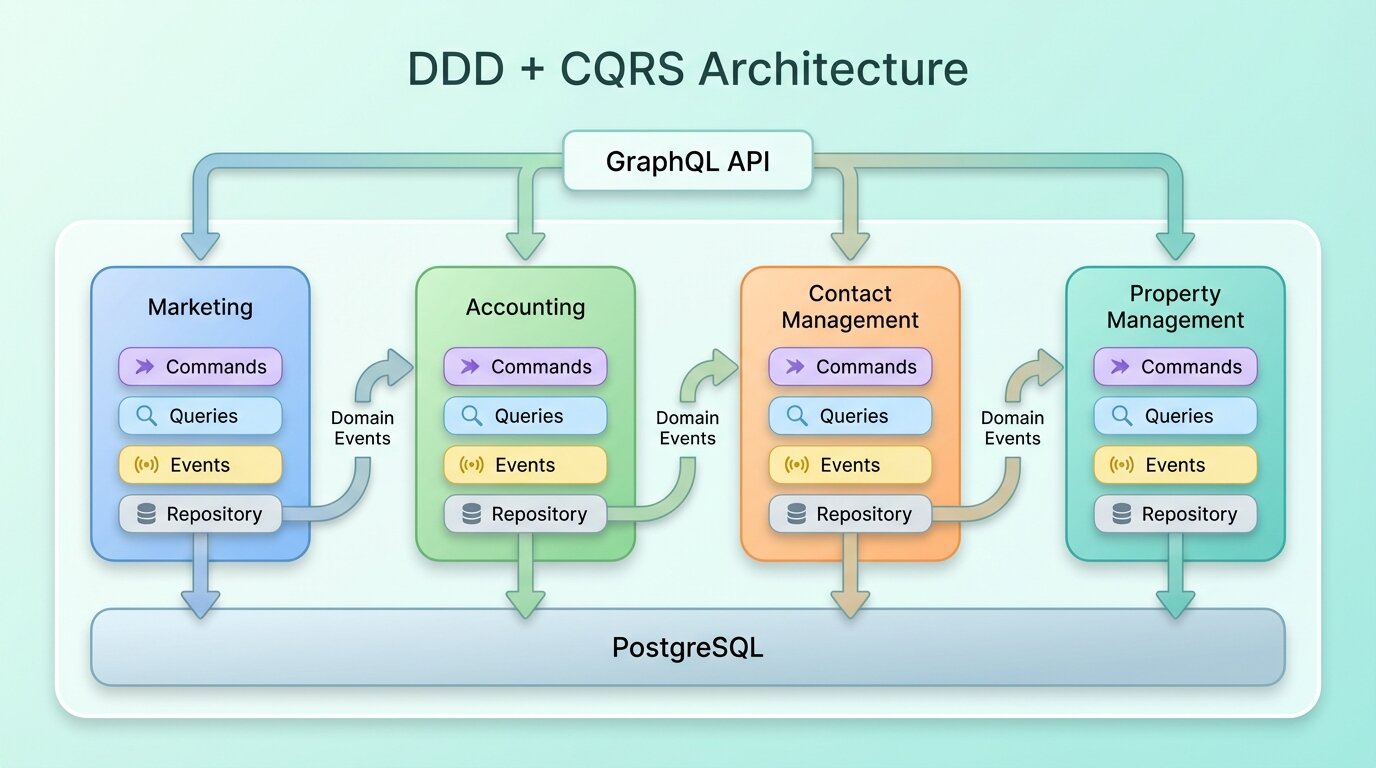
Domain-Driven Design gave us bounded contexts. Each business area (marketing, accounting, contact management, property management, territory mapping) became its own module with its own models, business rules, and data access. A change to how campaigns work doesn’t ripple through accounting.
CQRS (Command Query Responsibility Segregation) separated our read and write paths. Write operations go through command handlers that enforce business rules. Read operations go through query handlers optimized for the specific data shape the consumer needs. This matters a lot in real estate software. The dashboard might need a denormalized view joining properties, campaigns, and contacts. The import process needs strict validation and transactional writes. Those are very different access patterns.
We ended up with around 83 command and query handlers across the system, each focused on a single operation.
Architecture walkthrough
Every domain module follows the same internal structure: models, repositories, command handlers, query handlers, GraphQL resolvers, and event listeners. Writes go through commands, reads through queries, and cross-domain communication happens via events.
This consistency across 37 modules is the best thing about the architecture. A new developer learns the pattern once and can navigate any module. The folder structure is the documentation. No wiki needed.
Dependency injection with Inversify
We use Inversify for dependency injection, which keeps modules decoupled. A command handler in the marketing module doesn’t directly import accounting; it receives the dependency through the container. Testing is straightforward (swap real implementations for mocks), and we avoid the circular dependency problems that plague large Node.js codebases.
The repository pattern
Every module accesses data through a repository that abstracts the ORM details. Command handlers never touch Sequelize directly. They work with domain models and repository methods. This paid off when we needed to optimize specific queries with raw SQL. The business logic didn’t change at all.
Not every domain needs full CQRS
One thing we figured out along the way: full CQRS is overkill for simple domains. The property domain, with its complex search requirements, filtering, and relational data, genuinely benefits from separate read and write paths. The settings domain, which is mostly CRUD with minimal business rules, doesn’t need command and query handlers. A simpler service pattern works fine there.
We apply CQRS selectively. Complex domains get the full treatment. Simpler ones get a lighter pattern. The module boundary and naming conventions stay consistent regardless; the internal implementation varies based on what the domain actually needs.
The trade-offs
More boilerplate per feature
Adding a new feature to a DDD/CQRS codebase involves more files than a typical Express handler. You write the command or query, the handler, the repository method, the resolver, and maybe an event listener. For a simple CRUD endpoint, it feels like a lot.
But the discipline pays off when a feature needs to evolve. Adding validation, emitting events, changing the data shape for reads: you know exactly where each concern lives. In a flat service architecture, those concerns get tangled together and become harder to change safely.
Discipline required
DDD requires every developer to understand and follow the conventions. Someone used to writing Express handlers might be tempted to put business logic in a resolver or access the database directly from a command handler. Code review catches this, especially with new team members.
We found that pair programming during the first week of onboarding, walking through one full feature across the DDD layers, was the most effective way to get the patterns to stick.
Long-term maintainability
The architecture has held up over years of development across three different companies and teams. New developers can be productive within days because the patterns are consistent. Performance issues can be isolated to specific query handlers without touching business logic. New integrations get added as modules without modifying existing domains.
At 37 modules and 168K lines, the codebase is still easy to navigate and test. That’s how I judge whether an architecture decision was right: not how it looks in week one, but how it holds up in year three.
What we learned
- Consistent folder naming across dozens of modules is the best documentation we have. New developers orient themselves through structure, not wikis.
- Not every domain needs full CQRS. We apply it selectively to complex domains and use lighter patterns for simple ones.
- Inversify for dependency injection keeps modules isolated and testable. Without it, circular dependency problems would have killed us.
- The repository pattern means we can swap out query implementations or optimize with raw SQL without touching business logic.
- DDD feels heavy in week one. By year three, you’re glad you did it.